Apache Arrowの統計情報を使ったログ検索の爆速化
PostgreSQLにはBRINインデックス(Block Range Index)という機能があり、ログデータに付属するタイムスタンプ値など、近しい値を持ったデータが物理的に近接するという特徴を持っているとき、検索範囲を効率的に絞り込むために使用する事ができる。
この機能はPG-Stromでも対応しており、その詳細は以前のエントリでも解説している。
かいつまんで説明すると、時系列のログデータのように大半が追記(Insert-Only)であり、かつタイムスタンプ値のように近しい値同士が近接している場合、1MBのブロック((pages_per_rangeがデフォルトの128の場合、8kB * 128 = 1MB))ごとにその最小値/最大値を記録しておくことで『明らかに検索条件にマッチしない範囲』を読み飛ばす事ができる。
例えば以下の例であれば、WHERE ymd BETWEEN '2016-01-01' AND '2016-12-31'という検索条件は、ブロック内に含まれる個々の行をチェックしなくとも、最小値・最大値を参照すれば1番目と5番目のブロックに該当する行が無いのは自明である。そのため、検索条件にマッチする可能性のある2,3,4番目のブロックのみを読み出せばよい、というのがBRINインデックスの考え方である。
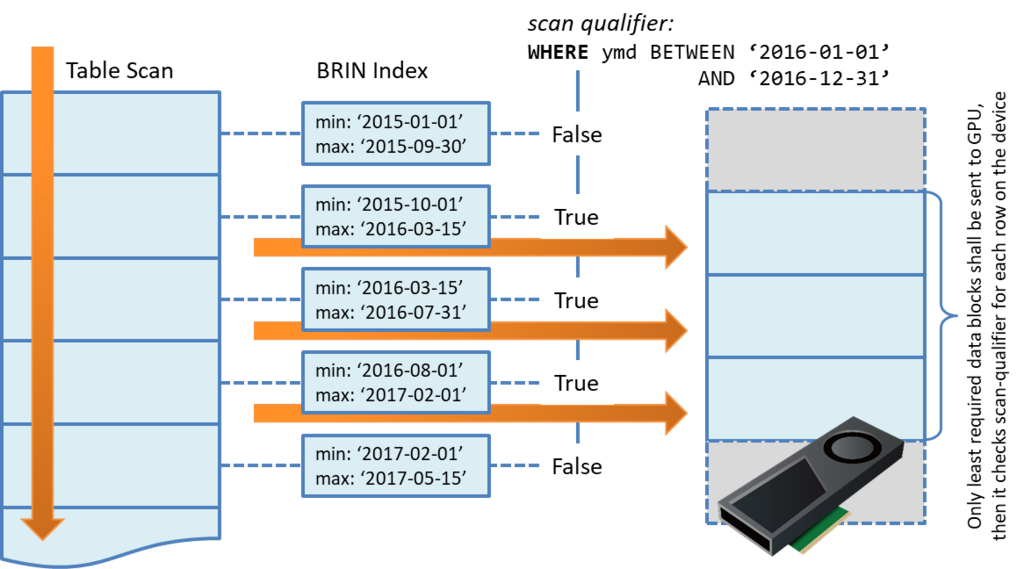
なお、B-treeインデックスとは異なり、BRINインデックスは個々の行を指し示すデータを持っていないため、1MBのブロック単位で読む/読まないを決めた後は、全件スキャンと同じ処理となる。
Apache Arrowに統計情報を埋め込む
話を Apache Arrow 形式に戻す。
Apache Arrow は列フォーマットの構造化データ形式であるが、例えば『このArrowファイルは1億件のデータを保持している』と言っても、単純に要素数1億の配列が並んでいるわけではない。
内部的にはRecord-Batchと呼ばれるブロックが複数並んだ構造となっており、このブロックの内側に、例えば1億件のうち100万件といったより小規模なデータの配列を保持している。(こうしたデータ構造を取る事により、より追記を行いやすくするという狙いがあるものと思われる。)

ファイルの末尾にはフッタ(Footer)があり、ここを読めば、ファイルのどこにRecord-Batchが配置されているかが分かる。
それと同時に、フッタにはデータ構造の定義を記述する Schema Definition の部分がある。これは基本的にはファイル先頭の Schema Definition のコピーであるものの、custom_metadataフィールドに独自のKey-Value値を埋め込んで書き込む程度の事は認められているようである。
このcustom_metadataフィールドは、テーブルだけでなく、カラムにも付与する事ができる。
そうすると、どういった使い方ができるか。フィールド毎のKey-Value値として、Record-Batchごとの最小値/最大値の配列(以下、統計情報)をApache Arrowファイルに埋め込む事ができる。
しかもこれはフッタ領域なので、Apache Arrowファイルを追記して Record-Batch を更新するたびに、統計情報をアップデートして書き直す事までできる。Yeah!!
pg2arrow の --stat オプション
早速、統計情報付きのApache Arrowファイルを生成してみる事にする。
これにはpg2arrowコマンドの--statオプションを使用する事ができ、統計情報を埋め込む対象列を指定する。現在のところ、Int、FloatingPoint、Decimal、Date、Time、Timestampの各データ型に対応している。
$ pg2arrow -d postgres -o /dev/shm/flineorder_sort.arrow -t lineorder_sort --stat=lo_orderdate --progress RecordBatch[0]: offset=1640 length=268437080 (meta=920, body=268436160) nitems=1303085 RecordBatch[1]: offset=268438720 length=268437080 (meta=920, body=268436160) nitems=1303085 RecordBatch[2]: offset=536875800 length=268437080 (meta=920, body=268436160) nitems=1303085 RecordBatch[3]: offset=805312880 length=268437080 (meta=920, body=268436160) nitems=1303085 RecordBatch[4]: offset=1073749960 length=268437080 (meta=920, body=268436160) nitems=1303085 RecordBatch[5]: offset=1342187040 length=268437080 (meta=920, body=268436160) nitems=1303085 RecordBatch[6]: offset=1610624120 length=268437080 (meta=920, body=268436160) nitems=1303085 RecordBatch[7]: offset=1879061200 length=268437080 (meta=920, body=268436160) nitems=1303085 RecordBatch[8]: offset=2147498280 length=268437080 (meta=920, body=268436160) nitems=1303085 RecordBatch[9]: offset=2415935360 length=55668888 (meta=920, body=55667968) nitems=270231 $ ls -lh /dev/shm/flineorder_sort.arrow -rw-r--r--. 1 kaigai users 2.4G 7月 19 10:45 /dev/shm/flineorder_sort.arrow
上記の例は、タイムスタンプに相当するlo_orderdate列でソート済みの*1テーブルをダンプし、Apache Arrowファイルとして保存したもの。
生のメタデータを可読な形式でダンプしてみると、確かにlo_orderdate列のフィールド定義にmin_valuesおよびmax_valuesのメタデータが埋め込まれ、それぞれ19920101とか19920919とか「それっぽい」値が見えている。

なお、custom-metadataを用いたデータの埋め込みはApache Arrow形式で認められているものなので、例えば、PG-Stromのコードベースと全く関係のない PyArrow を使って上記のファイルを読み出す場合でも、きちんとメタデータとして認識される。
(特にスキャンの最適化などにも使われないが)
$ python3
Python 3.6.8 (default, Aug 24 2020, 17:57:11)
[GCC 8.3.1 20191121 (Red Hat 8.3.1-5)] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import pyarrow as pa
>>> X = pa.RecordBatchFileReader('/dev/shm/flineorder_sort.arrow')
>>> X.schema
lo_orderkey: decimal(30, 8)
lo_linenumber: int32
lo_custkey: decimal(30, 8)
lo_partkey: int32
lo_suppkey: decimal(30, 8)
lo_orderdate: int32
-- field metadata --
min_values: '19920101,19920919,19930608,19940223,19941111,19950730,1996' + 31
max_values: '19920919,19930608,19940223,19941111,19950730,19960417,1997' + 31
lo_orderpriority: fixed_size_binary[15]
lo_shippriority: fixed_size_binary[1]
lo_quantity: decimal(30, 8)
lo_extendedprice: decimal(30, 8)
lo_ordertotalprice: decimal(30, 8)
lo_discount: decimal(30, 8)
lo_revenue: decimal(30, 8)
lo_supplycost: decimal(30, 8)
lo_tax: decimal(30, 8)
lo_commit_date: fixed_size_binary[8]
lo_shipmode: fixed_size_binary[10]
-- schema metadata --
sql_command: 'SELECT * FROM lineorder_sort'
統計情報を使って Apache Arrow のスキャンを最適化する
さて、埋め込んだ統計情報も、集計処理の段でこれを参照しなければカピバラに小判、カピバラに真珠である。
という事で、Apache ArrowファイルをPostgreSQLからスキャンするためのArrow_Fdwに統計情報を参照するための機能を付加してみた。
検索条件が統計情報を含む列を参照し、その大小関係に基づく絞り込みを行う場合、統計情報に基づいて『明らかに無駄なRecord-Batch』の読み出しをスキップする。
postgres=# IMPORT FOREIGN SCHEMA flineorder_sort
FROM SERVER arrow_fdw INTO public
OPTIONS (file '/dev/shm/flineorder_sort.arrow');
IMPORT FOREIGN SCHEMA
postgres=# EXPLAIN ANALYZE
SELECT count(*) FROM flineorder_sort
WHERE lo_orderpriority = '2-HIGH'
AND lo_orderdate BETWEEN 19940101 AND 19940630;
QUERY PLAN
------------------------------------------------------------------------------------------
Aggregate (cost=33143.09..33143.10 rows=1 width=8) (actual time=115.591..115.593 rows=1loops=1)
-> Custom Scan (GpuPreAgg) on flineorder_sort (cost=33139.52..33142.07 rows=204 width=8) (actual time=115.580..115.585 rows=1 loops=1)
Reduction: NoGroup
Outer Scan: flineorder_sort (cost=4000.00..33139.42 rows=300 width=0) (actual time=10.682..21.555 rows=2606170 loops=1)
Outer Scan Filter: ((lo_orderdate >= 19940101) AND (lo_orderdate <= 19940630) AND (lo_orderpriority = '2-HIGH'::bpchar))
Rows Removed by Outer Scan Filter: 2425885
referenced: lo_orderdate, lo_orderpriority
Stats-Hint: (lo_orderdate >= 19940101), (lo_orderdate <= 19940630) [loaded: 2, skipped: 8]
files0: /dev/shm/flineorder_sort.arrow (read: 217.52MB, size: 2357.11MB)
Planning Time: 0.210 ms
Execution Time: 153.508 ms
(11 rows)
postgres=# SELECT count(*) FROM flineorder_sort
WHERE lo_orderpriority = '2-HIGH'
AND lo_orderdate BETWEEN 19940101 AND 19940630;
count
--------
180285
(1 row)上の実行計画は、先ほどのApache ArrowファイルをPostgreSQLから外部テーブルとして参照できるようにしたflineorder_sortに、lo_orderdate列とそれ以外の検索条件を付加して検索したものである。
実行計画のStats-Hintを見ると、lo_orderdate BETWEEN 19940101 AND 19940630を展開した(lo_orderdate >= 19940101), (lo_orderdate <= 19940630)という条件を用いて不要Record-Batchの読み飛ばしを行い、全体で10個のRecord-Batchがある中で8個をスキップ、2個だけを読み出したと出力されている。
その結果、読み出した2個のRecord-BatchをGPUで評価し、2425885行を除去して残りが180285行であると集計している。
統計情報を使わない場合はどうなるのか?
以下の実行結果をご覧頂きたい。
postgres=# SET arrow_fdw.stats_hint_enabled = off;
SET
postgres=# EXPLAIN ANALYZE
SELECT count(*) FROM flineorder_sort
WHERE lo_orderpriority = '2-HIGH'
AND lo_orderdate BETWEEN 19940101 AND 19940630;
QUERY PLAN
------------------------------------------------------------------------------------------
Aggregate (cost=33143.09..33143.10 rows=1 width=8) (actual time=185.985..185.986 rows=1 loops=1)
-> Custom Scan (GpuPreAgg) on flineorder_sort (cost=33139.52..33142.07 rows=204 width=8) (actual time=185.974..185.979 rows=1 loops=1)
Reduction: NoGroup
Outer Scan: flineorder_sort (cost=4000.00..33139.42 rows=300 width=0) (actual time=10.626..100.734 rows=11997996 loops=1)
Outer Scan Filter: ((lo_orderdate >= 19940101) AND (lo_orderdate <= 19940630) AND (lo_orderpriority = '2-HIGH'::bpchar))
Rows Removed by Outer Scan Filter: 11817711
referenced: lo_orderdate, lo_orderpriority
files0: /dev/shm/flineorder_sort.arrow (read: 217.52MB, size: 2357.11MB)
Planning Time: 0.186 ms
Execution Time: 231.942 ms
(10 rows)
postgres=# SELECT count(*) FROM flineorder_sort
WHERE lo_orderpriority = '2-HIGH'
AND lo_orderdate BETWEEN 19940101 AND 19940630;
count
--------
180285
(1 row)arrow_fdw.stats_hint_enabledにoffを設定すると、統計情報を使わなくなる。
その場合、Rows Removed by Outer Scan Filterが2,425,885から11,817,711へと増加しているが、条件に該当しない行を除いた最終結果は180285で同一である。
つまり、”明らかにマッチする行が一つもない” Record-Batch を読み出した挙句、検索条件をGPUで評価してフィルタしているワケである。大変にご苦労様なことである。
サイズの大きなApache Arrowファイルによるベンチマーク
数GB程度のスケールだと中々差が見えないので、60億件規模のlineorderテーブル((ログデータに似た構造とするため、予めlo_orderdateでソートしておいた))を検索するワークロードで、クエリの応答時間を比較してみた。
元のPostgreSQLテーブルでは875GBあり、これをApache Arrowにダンプすると682GBあった*2。
単純にストレージからの読み出しの部分だけに絞って考えても、PostgreSQLテーブル(Heap)のような行データであれば、集計処理を行うために全てのデータを読み出さねばならない。
一方、Apache Arrowのような列形式データの場合は被参照列のみ読み出せば集計処理を行う事ができるため、相対的にI/O量が小さくなり、それが高速な処理速度の要因のひとつとなっている。

これに加えて、予め収集した統計情報を元にRecord-Batchを読み飛ばすという事は、列方向に加えて行方向に関してもI/O量を小さくするという事と同義である。どの程度、集計クエリの応答速度が短くなるのか実測してみた。
測定パターンの全てで概ね妥当なクエリ実行計画を生成するサンプルとして、Star Schema BenchmarkのQ1_2をピックアップしてみた。
select sum(lo_extendedprice*lo_discount) as revenue from flineorder_sort, date1 where lo_orderdate = d_datekey and d_yearmonthnum = 199401 and lo_discount between 4 and 6 and lo_quantity between 26 and 35;
この人は、lo_orderdateが『1994年1月』のデータを抽出するように作られている。
ただ、これはdate1テーブルとのJOINによって記述されており、そのままでは統計情報を用いて不要Record-Batchをスキップする形には落ちてくれない。そのため、以下のように一部クエリを修正して条件を付加する事にした。
select sum(lo_extendedprice*lo_discount) as revenue from flineorder_sort, date1 where lo_orderdate = d_datekey and d_yearmonthnum = 199401 and lo_discount between 4 and 6 and lo_quantity between 26 and 35; and lo_orderdate between 19940101 and 19940131;
その結果が、以下のグラフである。縦軸は Q1_2 クエリの応答時間であるので、結果が小さいほど性能が良いという事ができる。
また、行データをスキャンするパターン(青、橙)に関しては、Apache Arrowファイルをマップした flineorder_sort テーブルではなく、その元になった lineorder_sort テーブルをスキャンした。

ご覧の通り、I/O量の低減が功を奏してかなり極端な結果が出ている。
スケールが違いすぎて分かりにくいが、PostgreSQL v13.3で254秒を要した60億件のレコードのスキャンが、GPUDirect SQL、Apache Arrow、および統計情報による読み飛ばしの効果により1.2秒弱で終わっている。
以下のEXPLAIN ANALYZE結果を見ると、全体で2725個のRecord-Batchを含み、その大半(2688個)は検索条件に該当する行ナシとして捨ててしまっている。GPUが高速とはいえ、そもそも「何もしない」に勝る結果は無いのであるから、妥当な結果と言えるだろう。
postgres=# explain analyze
select sum(lo_extendedprice*lo_discount) as revenue
from flineorder_sort, date1
where lo_orderdate = d_datekey
and d_yearmonthnum = 199401
and lo_discount between 4 and 6
and lo_quantity between 26 and 35
and lo_orderdate between 19940101 and 19940131;
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------------------------------- Finalize Aggregate (cost=15117511.53..15117511.54 rows=1 width=8) (actual time=1042.000..1092.485 rows=1 loops=1)
-> Gather (cost=15117511.31..15117511.52 rows=2 width=8) (actual time=846.545..1092.475 rows=3 loops=1)
Workers Planned: 2
Workers Launched: 2
-> Partial Aggregate (cost=15116511.31..15116511.32 rows=1 width=8) (actual time=781.303..781.308 rows=1 loops=3)
-> Hash Join (cost=25060.71..15116511.29 rows=4 width=8) (actual time=435.810..719.086 rows=1404451 loops=3)
Hash Cond: (flineorder_sort.lo_orderdate = date1.d_datekey)
-> Parallel Custom Scan (GpuScan) on flineorder_sort (cost=24981.37..15116431.13 rows=312 width=12) (actual time=435.301..553.115 rows=1404451 loops=3)
GPU Filter: ((lo_discount >= 4) AND (lo_discount <= 6) AND (lo_quantity >= 26) AND (lo_quantity <= 35) AND (lo_orderdate >= 19940101) AND (lo_orderdate <= 1
9940131))
Rows Removed by GPU Filter: 77197339
GPU Preference: GPU0 (NVIDIA A100-PCIE-40GB) with GPUDirect SQL
referenced: lo_orderdate, lo_quantity, lo_extendedprice, lo_discount
Stats-Hint: (lo_orderdate >= 19940101), (lo_orderdate <= 19940131) [loaded: 37, skipped: 2688]
files0: /opt/nvme0/flineorder_sort.arrow (read: 89.37GB, size: 681.05GB)
-> Hash (cost=78.95..78.95 rows=31 width=4) (actual time=0.472..0.473 rows=31 loops=3)
Buckets: 1024 Batches: 1 Memory Usage: 10kB
-> Seq Scan on date1 (cost=0.00..78.95 rows=31 width=4) (actual time=0.140..0.464 rows=31 loops=3)
Filter: (d_yearmonthnum = '199401'::numeric)
Rows Removed by Filter: 2525
Planning Time: 4.661 ms
Execution Time: 1190.959 ms
(21 rows)
PostgreSQLパーティションとの比較
最後に、タイムスタンプ等を用いたデータ分散と集計処理の際の読み飛ばしという点で、類似する機能を有する PostgreSQL パーティションについても考察する。

PostgreSQLパーティションの場合、親テーブルと全く同一のスキーマ定義を持つ子テーブルに、他の子テーブルと重複しないようパーティションキー値の取り得る範囲を設定する。
通常のPostgreSQLテーブルの場合、これはINSERT/UPDATE/DELETE処理の際に自動的に子テーブル側の更新処理に振り分けられ、テーブルの内容に矛盾が生じる事はない。
一方、Apache Arrowファイルをマッピングする場合には、パーティション子テーブルとして振舞うArrow_Fdw外部テーブルに紐づいたApache Arrowファイルの内容に責任を持つのは、ユーザやDB管理者の役割である。
ログを保存するApache Arrowファイルを特定の時刻にバチッと切り替えるなら対応可能かもしれないが、例えば、一定のサイズに達したApache Arrowファイルは一旦クローズして新しいファイルを作ったり、非同期でマルチスレッドが次々とデータを書き出すために、明確なタイムスタンプの区切りを設けるのが難しい場合、パーティション設定と辻褄を合わせるのは中々難しい作業となる。
最小/最大値の統計情報であれば、機械的に Apache Arrow ファイルに埋め込まれるだけなので、明確な境界値を設ける必要はなく、また、各Apache Arrowファイルに含まれるタイムスタンプ値に関しても、これを管理者が意識する必要はない。
つまり、どこかのディレクトリを『時系列ログをApache Arrow形式で放り込む場所』と決めてしまいさえすれば、あとはポンポンとファイルをコピーするだけで、それを分析する事ができるようになるのである。
現在のところ、Apache Arrowファイルに最小/最大値の統計情報を埋め込む事ができるのはpg2arrowだけであるが、Apache Arrowファイルの構造上、末尾のフッタ部分だけを書き換えれば統計情報を付加する事ができるようになるの。
したがって、他のツールによって生成されたファイルであっても、簡単なバッチ処理で統計情報を付加できるようにする事ができるハズであるし、そういったツールは追って提供する事としたい。