構想は半年ほど前?ここ一ヶ月ほど集中して開発に取り組んでいた、Fluentd向けApache Arrowプラグインがようやく動くようになったので、今回はこちらのモジュールについてご紹介します。
そもそもPG-Stromは、IoT/M2M領域で大量に発生するデータを高速に処理できますというのがセールスポイントで、GPU-Direct SQLはじめ、各種の機能によってそれを実現しているワケですが、実際に運用する際には、発生したデータを『どうやってSQLで処理できるようDBにインポートするか?』という問題があります。
例えば、PostgreSQLに一行ずつINSERTするというのも一つの解です。ただし、単純なI/Oに比べると、DBへの書き込みはどうしても処理ボトルネックになりがちです。
そこで、大量に収集するログデータを、少ない時間ロスで(つまり一時ファイルに保存したデータを再度DBにインポートするなどの手間をかける事なく)検索や集計できる状態に持って行くために、以下のように Fluentd から Apache Arrow 形式ファイルを出力し、それを直接 PG-Strom から読み出すというスキームを作りました。
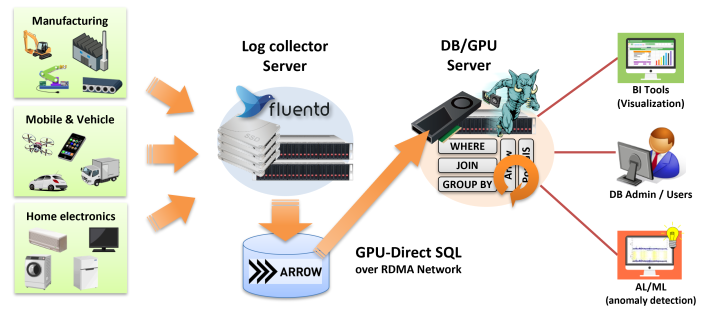
Fluentdとは Treasure Data の古橋貞之氏によって開発されたログ収集ツールで、SyslogのようなサーバログからIoT/M2M機器のデバイスログに至るまで、多種多様なログデータを集積・保存するために事実上のスタンダードとして利用されているソフトウェアです。
Ruby で記述されたプラグインを追加する事で、ログデータの入出力や加工を自在にカスタマイズすることができます。
arrow-file プラグイン
Fluentdのプラグインにはいくつかカテゴリがあり、外部からログを受け取るInputプラグイン、ログを成形するParserプラグイン、受信したログを一時的に蓄積するBufferプラグイン、ログを出力するOutputプラグイン、などの種類があります。
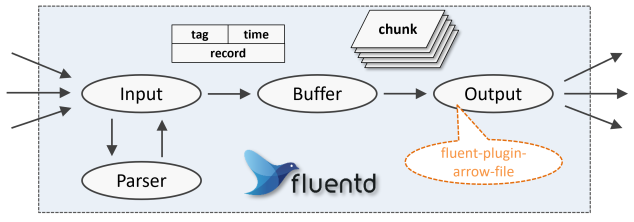
Fluentdがログを受け取ると、Input/Parserプラグインによってログは共通の内部形式へと変換されます。
これは、ログの振り分けに利用できる識別子のtag、ログのタイムスタンプtimeおよび、生ログを整形した連想配列であるrecordです。
Bufferプラグインは、ログを Output プラグインに渡して書き出すまでの間、一時的にこれを保持します。これにより、渡すまでの間、一時的にこれを保持します。これにより、複数レコードをまとめて書き込む事で出力のパフォーマンスが向上したり、障害時のリトライを単純化する事ができます。
最後に、OutputプラグインがBufferプラグインから渡されたログをそれぞれのプラグインに応じた出力先に書き出します。
今回、作成したfluent-plugin-arrow-fileモジュールは、この Output プラグインに相当するもので、出力先として指定されたファイルに Apache Arrow ファイル形式で書き込みます。
インストール
ここでは、Treasure Data社の提供する Fluentd の安定板 td-agent を利用します。
また、arrow-fileプラグインのインストールにはrake-compilerモジュールも必要ですので、予めインストールしておきます。
Fluentdのインストール詳細については、こちらを参照してください。
$ curl -L https://toolbelt.treasuredata.com/sh/install-redhat-td-agent4.sh | sh $ sudo /opt/td-agent/bin/fluent-gem install rake-compiler
次に、PG-Stromのソースコードをダウンロードし、fluentd ディレクトリ以下の物件をビルドします。
$ git clone https://github.com/heterodb/pg-strom.git $ cd pg-strom/fluentd $ make TD_AGENT=1 gem $ sudo make TD_AGENT=1 install
Fluentdのプラグインがインストールされている事を確認するため、以下のコマンドを実行します。
fluent-plugin-arrow-fileが表示されていれば、インストールは成功です。
動かしてみる
では実際に動かしてみる事にします。
簡単な例として、ローカルのApache Httpdサーバのログを監視し、それをフィールド毎にパースしてApache Arrow形式ファイルに書き込みます。
<source>で/var/log/httpd/access_logをデータソースとして指定しているほか、apache2のParseプラグインを用いて、host, user, time, method, path, code, size, referer, agentの各フィールドを切り出しています。
(これは公式サイトのExampleからのコピペです)
後半の<match>以下がarrow-fileプラグインの設定です。
pathで出力先を指定しています。ここでは/tmp/mytest%Y%m%d.%p.arrowと記述していますが、書き込み時に、%Y、%m、%dはそれぞれ年、月、日に、%pはプロセスのPIDに置き換えられます。
schema_defsでは、出力先 Apache Arrow ファイルのスキーマ構造を定義します。
tsがタイムスタンプ、host、method、path、referer、agentがそれぞれ文字列(Utf8)で、codeとsizeはInt32で設定しています。
また、バッファに関してはもう少し大きなサイズを指定すべきですが、ここでは動作確認のため比較的小さなサイズ(4MB、200行)で、かつ書き出しのインターバルを10sに指定しています。実際にはPG-StromがGPU-Direct SQLを発動するのに向いたサイズのバッファサイズを指定する事をお勧めします。(例えばデフォルト値の 256MB など)
<source>
@typetail
path /var/log/httpd/access_log
pos_file /var/log/td-agent/httpd_access.pos
tag httpd
format apache2
<parse>
@typeapache2
expression /^(?<host>[^ ]*) [^ ]* (?<user>[^ ]*) \[(?<time>[^\]]*)\] "(?<method>\S+)(?: +(?<path>(?:[^\"]|\\.)*?)(?: +\S*)?)?" (?<code>[^ ]*) (?<size>[^ ]*)(?: "(?<referer>(?:[^\"]|\\.)*)" "(?<agent>(?:[^\"]|\\.)*)")?$/
time_format %d/%b/%Y:%H:%M:%S %z
</parse>
</source>
<match httpd>
@typearrow_file
path /tmp/mytest%Y%m%d.%p.arrow
schema_defs "ts=Timestamp[sec],host=Utf8,method=Utf8,path=Utf8,code=Int32,size=Int32,referer=Utf8,agent=Utf8"
ts_column "ts"
<buffer>
flush_interval 10s
chunk_limit_size 4MB
chunk_limit_records 200
</buffer>
</match>さて、td-agentを起動します。
sudo systemctl start td-agent
以下のように、Apache Httpdのログが path で設定した /tmp/mytest%Y%m%d.%p.arrow が展開された先である /tmp/mytest20220124.3206341.arrow に書き出されています。
中身を見てみると、それっぽい感じになっているのが分かります。
$ arrow2csv /tmp/mytest20220124.3206341.arrow --head --offset 300 --limit 10 "ts","host","method","path","code","size","referer","agent" "2022-01-24 06:13:42","192.168.77.95","GET","/docs/ja/js/theme_extra.js",200,195,"http://buri/docs/ja/fluentd/","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36" "2022-01-24 06:13:42","192.168.77.95","GET","/docs/ja/js/theme.js",200,4401,"http://buri/docs/ja/fluentd/","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36" "2022-01-24 06:13:42","192.168.77.95","GET","/docs/ja/img/fluentd_overview.png",200,121459,"http://buri/docs/ja/fluentd/","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36" "2022-01-24 06:13:42","192.168.77.95","GET","/docs/ja/search/main.js",200,3027,"http://buri/docs/ja/fluentd/","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36" "2022-01-24 06:13:42","192.168.77.95","GET","/docs/ja/fonts/Lato/lato-regular.woff2",200,182708,"http://buri/docs/ja/css/theme.css","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36" "2022-01-24 06:13:42","192.168.77.95","GET","/docs/ja/fonts/fontawesome-webfont.woff2?v=4.7.0",200,77160,"http://buri/docs/ja/css/theme.css","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36" "2022-01-24 06:13:42","192.168.77.95","GET","/docs/ja/fonts/RobotoSlab/roboto-slab-v7-bold.woff2",200,67312,"http://buri/docs/ja/css/theme.css","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36" "2022-01-24 06:13:42","192.168.77.95","GET","/docs/ja/fonts/Lato/lato-bold.woff2",200,184912,"http://buri/docs/ja/css/theme.css","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36" "2022-01-24 06:13:43","192.168.77.95","GET","/docs/ja/search/worker.js",200,3724,"http://buri/docs/ja/fluentd/","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36" "2022-01-24 06:13:43","192.168.77.95","GET","/docs/ja/img/favicon.ico",200,1150,"http://buri/docs/ja/fluentd/","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36"
これを PG-Strom のArrow_Fdwを用いてPostgreSQLにマッピングしてみます。
postgres=# IMPORT FOREIGN SCHEMA mytest
FROM SERVER arrow_fdw INTO public
OPTIONS (file '/tmp/mytest20220124.3206341.arrow');
IMPORT FOREIGN SCHEMA
postgres=# SELECT ts, host, path FROM mytest WHERE code = 404;
ts | host | path
---------------------+---------------+----------------------
2022-01-24 12:02:06 | 192.168.77.73 | /~kaigai/ja/fluentd/
(1 row)
postgres=# EXPLAIN SELECT ts, host, path FROM mytest WHERE code = 404;
QUERY PLAN
------------------------------------------------------------------------------
Custom Scan (GpuScan) on mytest (cost=4026.12..4026.12 rows=3 width=72)
GPU Filter: (code = 404)
referenced: ts, host, path, code
files0: /tmp/mytest20220124.3206341.arrow (read: 128.00KB, size: 133.94KB)
(4 rows)生成された Apache Arrow ファイルを外部テーブルとしてマッピングし、これをSQLから参照しています。
Fluentd側で成形されたログの各フィールドを参照する検索条件を与える事ができます。 上記の例では、HTTPステータスコード404のログを検索し、1件がヒットしています。
まとめ
以上のように、Fluentdで受け取ったログを Apache Arrow 形式ファイルとして書き出し、それをそのまま、つまり改めてデータをインポートする事なく PostgreSQL から参照する事ができる事が分かりました。
これは、ログ集積系のシステムから、検索・分析系のシステムへデータを移送するという手間なしにSQL処理を発行できる事を意味するほか、例えば、もう使わなくなった古いログデータをOS上でコピーして退避すれば、それだけでアーカイブ作業が終了します。(Apache Arrow形式の場合、ファイルにスキーマ構造も内包しているため、後になって『あれ?このテーブルのDDLは?』なんて事もありません)
加えて、Fluentdのarrow-fileプラグインはタイムスタンプに統計情報を付加する事もできるため、検索条件に日付時刻範囲の絞り込みを含むケースでは大幅な検索時間の高速化を見込むことができます。
kaigai.hatenablog.com
課題としては、現状、まだ「動くようになった」というレベルですので、実際に Fluentd のインスタンスを何台も立てて検証済みである、という訳ではありません。ですので、この辺はぜひ『一緒に検証しませんか?』という方がいらっしゃいましたら、お声がけいただければと思います。