半精度浮動小数点型(Float2)について
このエントリはPostgreSQL Advent Calendar 2021に参加しています。
実は、現在開発中の別の機能について書きたかったのですが、間に合いませんでした。反省。
そこで、急遽ネタを用意したのが、反省、はんせい、はんせいど…ふどうしょうすうてん(ピコーン!!
という事で、PostgreSQLで利用できる半精度浮動小数点型(float2)の事について書こうと思います。
半精度浮動小数点とは
Cで言えば32bitのfloatに対して64bitのdoubleを倍精度と呼ぶように、floatの半分である16bitの浮動小数点フォーマットが半精度浮動小数点形式です。
もちろん、データ量が少ない分、表現できる範囲や精度に制限はあるのですが、一方で必要なストレージ領域は小さく、またSIMDやGPUといったベクトル演算を行う場合にはメモリバスを有効活用できることから、機械学習の分野などで活用が進んでいます。
| 型名 | ビット幅 | 指数部 | 仮数部 |
|---|---|---|---|
| 倍精度 | 64bit | 11bit | 52bit |
| 単精度 | 32bit | 8bit | 23bit |
| 半精度 | 16bit | 5bit | 10bit |

PostgreSQL で float2 型を定義する
さて、この半精度浮動小数点型ですが、PostgreSQL本体ではまだ対応していません。
そもそもがApache Arrowとのデータ交換に必要であったので PG-Strom 拡張モジュールの一部として作成したモノ・・・ではあるのですが、別にこれ自体はGPUやNVMEを必要とするものではありませんので、これ単体を切り出して利用する事も可能です。
x86_64のCPUでは今のところ半精度浮動小数点をそのまま計算する事はできませんので、内部的にはこれをfloat4やfloat8に変換した上で演算を行っています。GPU側であればfloat2のまま計算する事もできるのですが。
float2 -> float4/float8 への変換はそれほど難しいことではありません。指数部も仮数部もより幅が広くなる方に動くので、float2で表現できる値は確実にfloat4/float8へと変換する事ができます。
例えば、float2からfloat4への変換は、このような単純なビット操作だけで可能です。
static inline float
fp16_to_fp32(half_t fp16val)
{
uint32_t sign = ((uint32_t)(fp16val & 0x8000) << 16);
int32_t expo = ((fp16val & 0x7c00) >> 10);
int32_t frac = ((fp16val & 0x03ff));
uint32_t result;
if (expo == 0x1f)
{
if (frac == 0)
result = (sign | 0x7f800000); /* +/-Infinity */
else
result = 0xffffffff; /* NaN */
}
else if (expo == 0 && frac == 0)
result = sign; /* +/-0.0 */
else
{
if (expo == 0)
{
expo = FP16_EXPO_MIN;
while ((frac & 0x400) == 0)
{
frac <<= 1;
expo--;
}
frac &= 0x3ff;
}
else
expo -= FP16_EXPO_BIAS;
expo += FP32_EXPO_BIAS;
result = (sign | (expo << FP32_FRAC_BITS) | (frac << 13));
}
return int_as_float(result);
}一方で、float4/float8 -> float2 への変換は、表現可能な範囲を超えると+/-Infに発散して島唄め、注意が必要です。
postgres=# select 65000::float2; float2 -------- 64992 (1 row) postgres=# select 66000::float2; float2 ---------- Infinity (1 row)
テーブル定義で float2 を用いる
半精度浮動小数点データ型は PG-Strom に含まれているため、以下のようにCREATE EXTENSIONコマンドでインストールする事ができます。
postgres=# CREATE EXTENSION pg_strom ;
CREATE EXTENSION
postgres=# \dT float2
List of data types
Schema | Name | Description
------------+--------+-------------
pg_catalog | float2 |
(1 row)早速、テーブルを定義して、データを流し込んでみます。
postgres=# CREATE TABLE fp16_test (
id int,
a float2,
b float2,
c float2,
d float2,
e float2,
f float2,
g float2,
h float2
);
postgres=# insert into fp16_test (select x, 1000*random(),
1000*random(),
1000*random(),
1000*random(),
1000*random(),
1000*random(),
1000*random(),
1000*random() from generate_series(1, 4000000) x);
INSERT 0 4000000一方、比較のために倍精度浮動小数点で同じようにテーブルを定義してみます。
postgres=# CREATE TABLE fp64_test (
id int,
a float8,
b float8,
c float8,
d float8,
e float8,
f float8,
g float8,
h float8
);
CREATE TABLE
postgres=# insert into fp64_test (select x, 1000*random(),
1000*random(),
1000*random(),
1000*random(),
1000*random(),
1000*random(),
1000*random(),
1000*random() from generate_series(1, 4000000) x);
INSERT 0 4000000あたり前の話ではありますが、大きくサイズが変わってきます。
(ただし、タプルのヘッダ 24バイト分は必ずくっつくので、単純に4倍違う、とはなりませんが)
postgres=# \d+
List of relations
Schema | Name | Type | Owner | Persistence | Size | Description
--------+-------------------+-------------------+--------+-------------+------------+-------------
public | fp16_test | table | kaigai | permanent | 199 MB |
public | fp64_test | table | kaigai | permanent | 386 MB |インデックスを張ることもできます。
postgres=# create index on fp16_test(b);
CREATE INDEX
postgres=# explain select * from fp16_test where b between 100 and 150;
QUERY PLAN
-----------------------------------------------------------------------------------------
Bitmap Heap Scan on fp16_test (cost=21238.43..61716.43 rows=1000000 width=20)
Recheck Cond: ((b >= '100'::double precision) AND (b <= '150'::double precision))
-> Bitmap Index Scan on fp16_test_b_idx (cost=0.00..20988.43 rows=1000000 width=0)
Index Cond: ((b >= '100'::double precision) AND (b <= '150'::double precision))
(4 rows)
なぜ半精度浮動小数点がGPUで好まれるのか?
最後に、なぜGPUアクセラレーションの文脈で半精度浮動小数点形式が使われるようになってきたのかを説明します。
GPUのように多数のコアが並列に動作するとき、とりわけNVIDIAのGPUではWarpと呼ばれる32スレッド単位でのスケジューリングが行われますが*1、隣接したコアが隣接したメモリからデータをロードする際、coalescingといって、一回のメモリトランザクションで複数スレッド分のデータをロードする事があります。
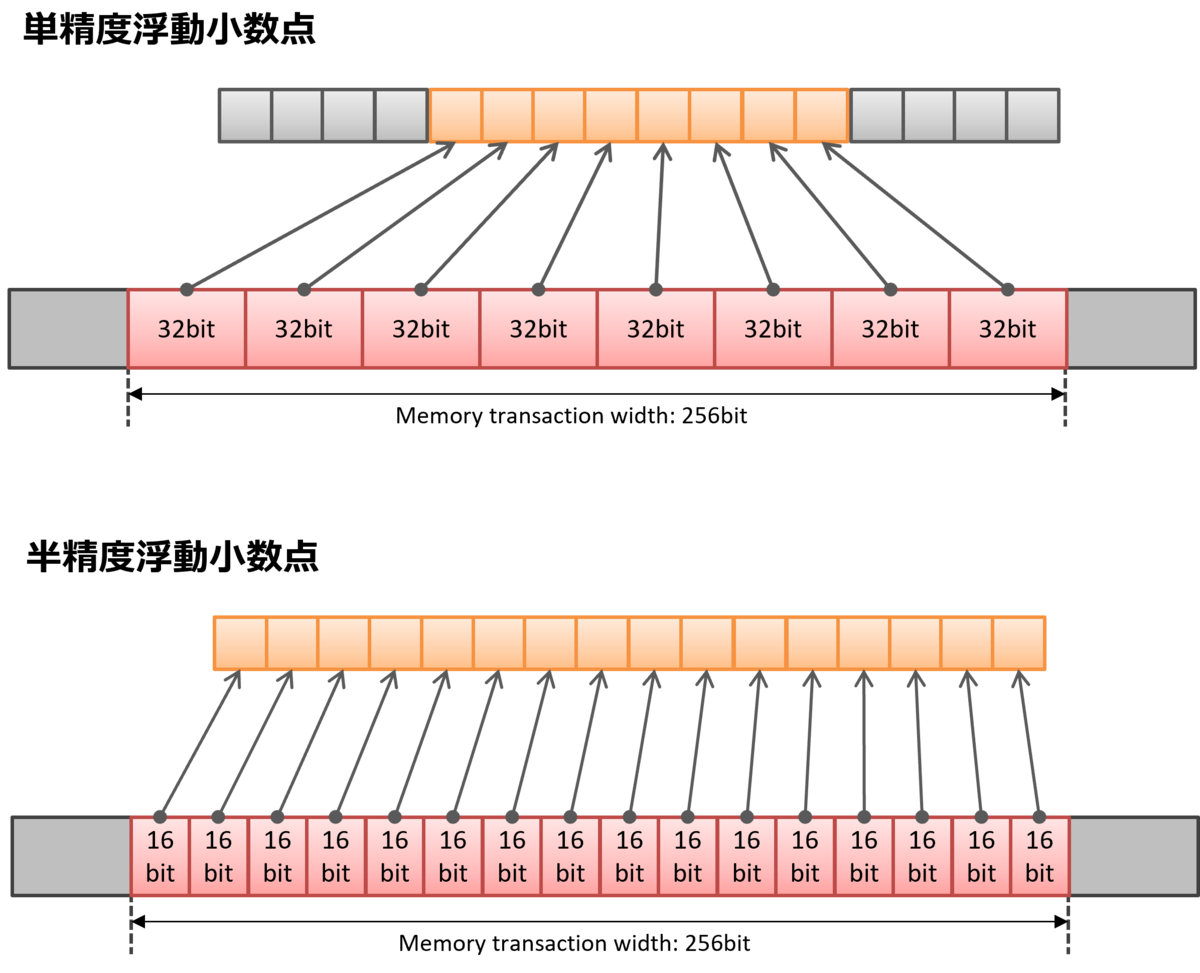
例えば、一回のメモリトランザクションで32byte(= 256bit)分のデータをL2キャッシュからロード*2できる場合、これが32bitの単精度浮動小数点なら、最大で8スレッドにデータを供給できる。一方、これが16bitの半精度浮動小数点なら、最大で16スレッドにデータを供給できるという計算になる。
通常、この手のワークロードであれば、メモリアクセスが最大の律速要因となってしまうので、そうすると、大量の計算をこなさねばならない機械学習のようなワークロードで、計算精度にある程度目をつぶれる(-1.0~1.0を十分に表現できればよい、など)場合には、単位時間あたりの計算量を増やすためにデータ量を削るという判断もアリとなる。
この辺については、CUDA C++ Programming GuideのMaximize Memory Throughputの章が詳しい。
言うまでもないが、これはデータが単純配列の形で並んでいるような場合の話で、例えばPostgreSQLの行データ(Heap形式)ではそれ以前の段階である。ただし、大抵のSQL条件式の検索というのは、特定の列を一回だけ参照してWHERE X BETWEEN 100 AND 200の条件を評価するものであるので、このためだけに行⇒列変換というのはリーズナブルではない。
(かつて一度実装したことがあり、やめたw)
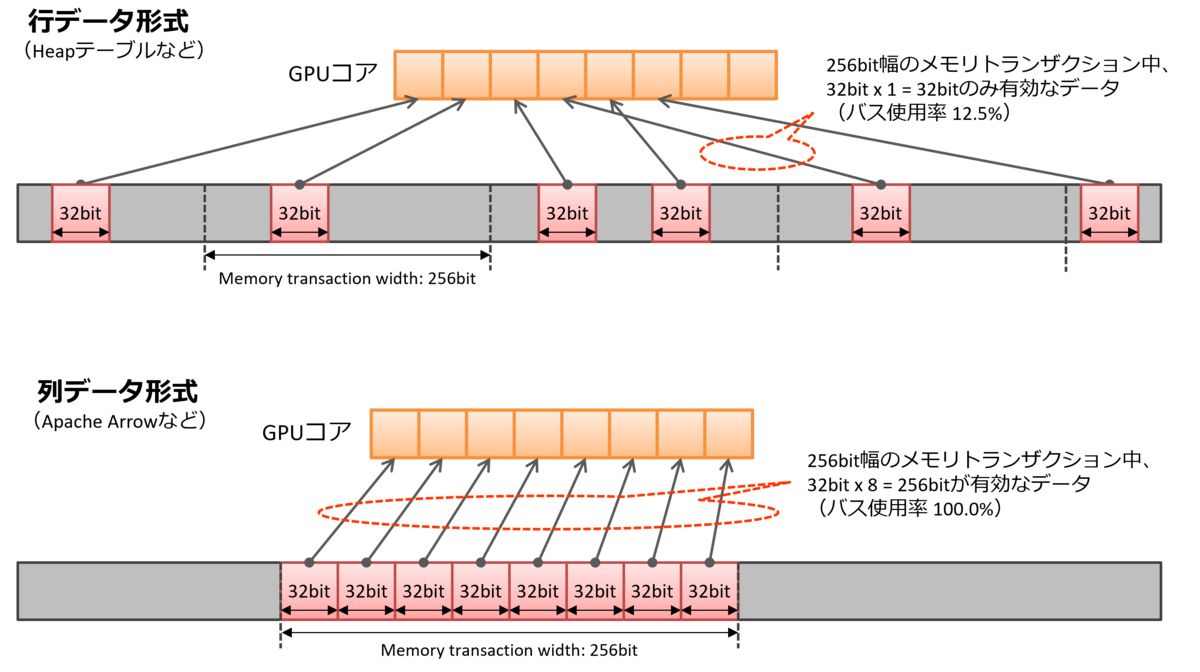
PG-Stromでも対応している Apache Arrow 形式や、あるいはGPU Cache機能のように、データが単純配列のように並ぶことになっているデータ形式であれば、こういったcoalesced accessによるメモリ読み出しの高速化効果というものも期待できるかもしれない。
(ただし、RAM => GPUへの転送というのがそれよりずっと遅いので、あまり差分は見えてこないかも…。)